Cet article présente une analyse des performances d'un cluster Ceph déployé par Easter-eggs au sein de son infrastructure d'hébergement.
Présentation générale de Ceph¶
La solution Ceph s’appuie sur un cluster de serveurs dit « standard » et d’éléments de stockage également standards pouvant mélanger différents types de disques mécaniques, SSD ou même NVMe.
L’architecture d’un cluster Ceph repose sur différents composants :
- des nœuds dit « mon » chargés d’orchestrer la répartition et l’accès aux données. Ils doivent être au minimum de 3.
- des nœuds dit « osd » contenant les disques où sont stockées les données.
Redondance¶
Elle est native (au niveau du cluster lui-même et du protocole « rbd » qui permet d’y accéder) et permet d’autoriser aussi bien la perte d’un ou plusieurs disques que d’un ou plusieurs serveurs (« osd » ou « mon »). Aucun système de type RAID n’est à mettre en œuvre. Ceph est conçu pour assurer l’intégrité des données, en cas d’incident réseau, serveur ou disque le cluster bloquera tout accès si les conditions de réplication configurées ne sont plus réunies. La répartition des données peut utiliser différents mécanismes :
- une réplication simple : chaque élément est écrit sur X disques en même temps. X étant paramétrable par « pool »(voir plus bas) de disques.
- une réplication avec correction d’erreur : fonctionne comme les systèmes RAID 5 ou 6, en utilisant des « disques » de « parité ».
Répartition de charge¶
Les opérations de lecture et écriture sont réparties sur l’ensemble des éléments de stockage.
Différents volumes de stockage¶
Les disques des serveurs « osd » sont placés dans des groupes nommés « pool », selon des règles permettant de définir :
- le type de disque à inclure dans le pool
- le type de serveur à inclure dans le pool
On peut ainsi créer des pools rapides, utilisant uniquement des disques SSD, ou des pools de stockage plus lent utilisant des disques mécaniques. Mais on peut également assurer une répartition géographique si les serveurs sont placés par groupes dans des emplacements distincts et mettre en œuvre par exemple un plan de reprise d’activité entre deux sites ou baies.
Evolutivité¶
Une capacité d’évolution simple : que ce soit pour avoir plus d’espace de stockage ou plus de performance, il suffit d’ajouter des disques aux serveurs existants ou d’ajouter des serveurs. Il n’est pas nécessaire d’avoir du matériel en tout point identique (mais un socle minimum doit être conservé si on ne veut pas dégrader les performances).
L'architecture réseau préconisée¶
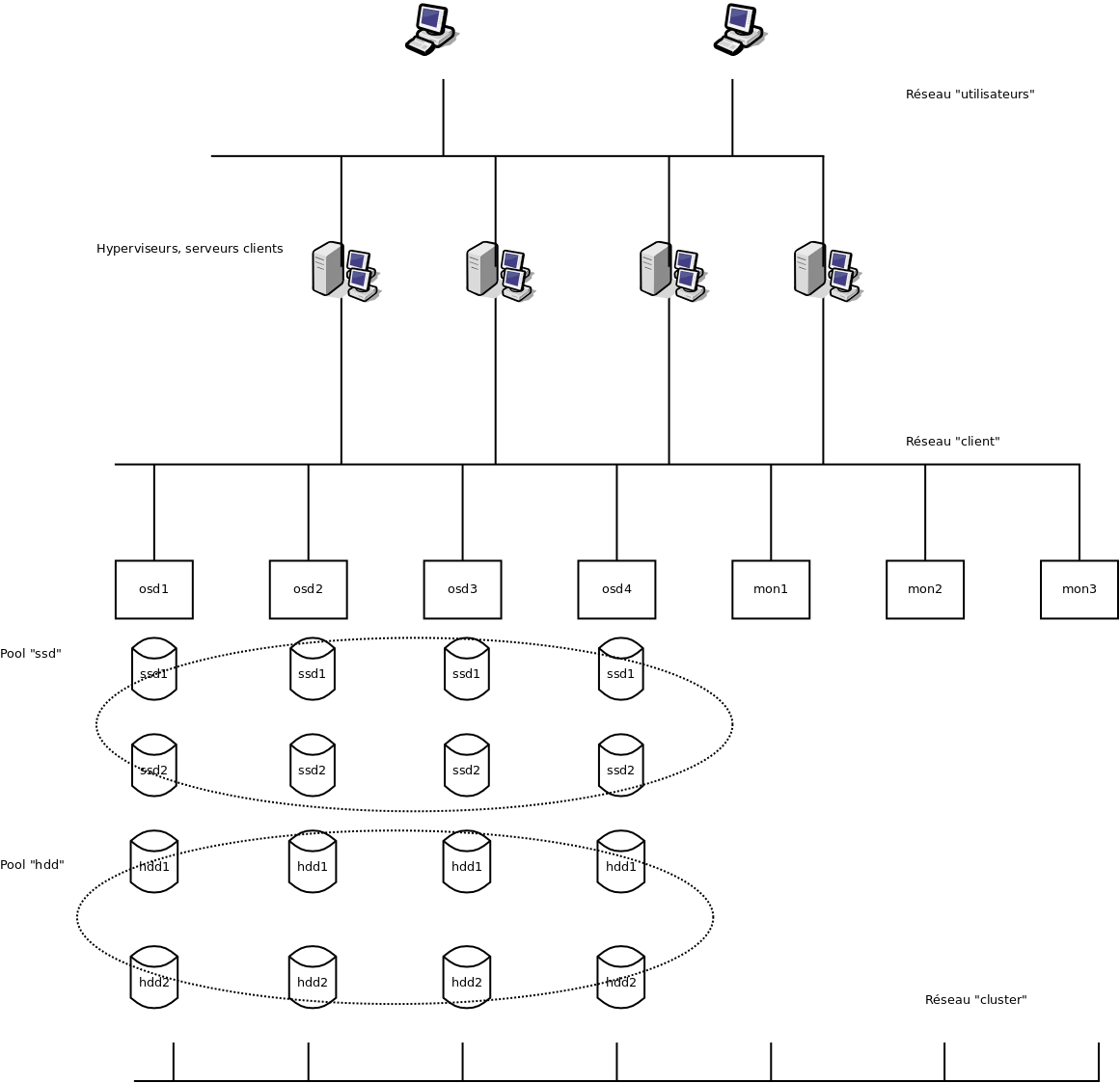
La solution Ceph nécessite idéalement 3 réseaux distincts :
Le réseau dit « cluster ».¶
C’est par celui-ci que sont répliquées les données lors des écritures, mais également pour maintenir la redondance lors de la perte d’un élément de stockage. Son débit doit en particulier être suffisant pour qu’un cluster qui vient de perdre un nœud (donc un certain nombre de copies des éléments stockés), quitte rapidement ce mode dégradé en recréant les copies manquantes sur les autres nœuds et revenir en situation optimale en terme de redondance. Dans la pratique il s’agit en général d’un réseau 10 Gb/s, parfois 40 Gb/s. Il doit également être redondant (deux interfaces par serveur, deux switchs) afin d’autoriser la panne et de faciliter la maintenance.
Le réseau dit « client ».¶
C’est ce réseau qui permet aux serveurs (hyperviseurs, serveurs de stockage, etc.) d’accéder aux données. Le débit et le niveau de redondance est fonction du besoin, mais on utilise souvent un réseau redondé en 10 Gb/s également.
Le réseau utilisateur¶
Il s’agit du réseau en général existant, permettant aux utilisateurs d’accéder aux serveurs d’applications.
Accès aux données¶
Ceph est un cluster stockant des « objets ». Différents protocoles permettent d’y accéder :
- radosgw : permet comme Swift ou Amazon S3 d’accéder directement au cluster pour y stocker des objets (fichiers ou autre), sans notion de « système de fichier »
- rbd : permet à des solutions de virtualisation de stocker directement des images disques.
- Cephfs : système de fichier s’appuyant directement sur le cluster Ceph.
Lorsqu’il s’agit de fournir des services hébergés sur des machines virtuelles, c’est donc souvent le protocole « rbd » qui est utilisé. Si un export de type CIFS ou NFS est nécessaire, il suffit de mettre en œuvre une machine virtuelle reliée à un disque via rbd et exportant les données via le protocole souhaité.
Performances¶
Ceph peut offrir une grande palette de performances selon les besoins. Easter-eggs configure généralement des clusters mixtes comportant un ou plusieurs pools de stockage rapide basés sur des SSD, et lent basé sur des disques mécaniques. Ce type d’architecture permet de répondre au besoin des solutions de virtualisations et applicatives déployées, en optimisant les coûts.
Il est à rappeler que Ceph est une solution logicielle de stockage distribué et qu’il n’est pas possible d’obtenir des performances égales à un stockage de même type (SSD par exemple) déployé directement sur un serveur hébergeant l’application. Néanmoins, la solution Ceph (comme ses concurrentes) permet de déployer de grand volumes de stockage et de disposer d’une souplesse bien supérieure au déploiement de serveurs physiques dédiés.
De fait, plutôt que de donner ici des données théoriques, Easter-eggs préfère montrer ici ce qu’il est possible de faire avec un cluster Ceph en environnement de production. Nous proposons ici des relevés d’un de nos clusters, utilisé en production, analysé sur une période de 90 jours. Ce cluster héberge une grande variété de machines virtuelles avec des solutions applicatives comme Nextcloud, SOGo, postfix, ERP, base de données, applications web, ...
Le cluster est composé de :
- 8 hyperviseurs libvirt/kvm faisant fonctionner 138 machines virtuelles variées (linux Debian majoritairement, mais également Ubuntu, Centos, MS Windows)
- 3 de ces hyperviseurs jouent également le rôle « mon » pour Ceph
- 4 serveurs osd Ceph comportant chacun 6 disques mécaniques 7 200trs/min et 2 disques SSD « entreprise/datacenter »
soit un total de 24 disques mécaniques et 8 disques SSD
- chaque serveur utilise un contrôleur équipé de mémoire cache, celle-ci est utilisée pour les disques mécaniques afin de bénéficier de plus d’IOPS en écriture (inutile voire contre productif pour des SSDs).
Les données observées sont les suivantes. Ne sont indiqués ici que des maximums :
| Type | IOPS (lecture) | Débit (lecture) | IOPS (écriture) | Débit (écriture) |
|---|---|---|---|---|
| Disque mécanique | 384 | 121 Mo/s | 406 | 61 Mo/s |
| SSD | 3 920 | 226 Mo/s | 2 906 | 112 Mo/s |
Remarques :
- ces données sont celles recueillies dans un contexte « Ceph », elles différent des données constructeur, ceux-ci donnant souvent des données très optimistes, en lecture/écriture séquentielle avec des tailles de bloc conséquents, ce qui ne se produit jamais dans la réalité ou coexiste des lectures/écritures séquentielles, aléatoires, mélangées dans des proportions variables.
À titre d’exemple, une écriture séquentielle utilisant des blocs de 4M (cas d’une copie d’un gros fichier) produira un débit proche du maximum, mais très peu d’IOPS ; à contrario les applications comme la messagerie font beaucoup de lecture/écritures de petits fichiers conduisant à un haut niveau d’iops avec peu de débit.
Disque mécanique (WD Gold 8To) :
- iops en lecture : non fourni
- débit en lecture : 255 Mo/s
- iops en écriture : non fourni
- débit en écriture 255 Mo/s
SSD (Intel D3-S4610 3.84 To) :
- iops en lecture : 96 000
- débit en lecture : 560 Mo/s
- iops en écriture : 42 000
- débit en écriture 510 Mo/s
Au sein d’une machine virtuelle :
| Type | IOPS (lecture) | Débit (lecture) | IOPS (écriture) | Débit (écriture) |
|---|---|---|---|---|
| Disque virtuel sur pool « lent » | 4 720 | 343 Mo/s | 1 530 | 58,1 Mo/s |
| Disque virtuel sur pool « rapide » | 8 430 | 756 Mo/s | 1 890 | 103 Mo/s |
Relevé global pour chaque pool :
| Type | IOPS (lecture) | Débit (lecture) | IOPS (écriture) | Débit (écriture) |
|---|---|---|---|---|
| Pool « lent » | 9 520 | 353 Mo/s | 2 150 | 165 Mo/s |
| Pool « rapide » | 10 700 | 367 Mo/s | 4 660 | 219 Mo/s |
Remarques :
Ce cluster n’est pas utilisé à son maximum dans tous les cas. Les maximums théoriques pour chaque pool peuvent être calculés de la façon suivante :
- pour la lecture, en prenant le maximum d’un OSD de ce pool, multiplié par le nombre d’OSD pour la lecture
- pour l’écriture, en prenant le maximum d’un OSD de ce pool, multiplié par le nombre d’OSD divisé par le nombre de replica (3).
Le résultat est donc fortement dépendant du nombre de disques (ici, beaucoup plus de hdd que de sdd). On obtiendrait donc :
Sur tous les OSD :
| Type | IOPS (lecture) | Débit (lecture) | IOPS (écriture) | Débit (écriture) |
|---|---|---|---|---|
| 24 disques mécaniques | 11 616 | 2 904 Mo/s | 3 248 | 488 Mo/s |
| 8 SSD | 31 360 | 1 808 Mo/s | 7 867 | 299 Mo/s |